The Hidden Truth About LLM Performance: Why Your Benchmark Results Might Be Misleading
The Hidden Truth About LLM Performance: Why Your Benchmark Results Might Be Misleading

I am the author of Napolab, a Natural Portuguese Language Benchmark. During my Master’s thesis, I reviewed past benchmarks in the literature and came to a surprising conclusion: for reasons that I will explain at the end of this article, the gap between general-purpose models and models trained specifically for Portuguese was much smaller than previously thought.
You are invited to interact with my findings on the Napolab Leaderboard, where I’ve listed all my research results along with other benchmarks aggregated from the internet. The images in this article are taken from the leaderboard. If this research has been useful to you, consider giving Napolab a star on GitHub.
The leading models on the Napolab benchmark are Transformer models that have been carefully fine-tuned on the tasks. These are compared with LLMs evaluated in a zero-shot fashion (thanks to the Open Portuguese LLM Leaderboard). The LLMs would probably perform better against the fine-tuned models if they had been allowed to use few-shot learning or RAG on the training and validation sets for the test queries.

The Benchmarking Crisis: Why Results Don’t Always Tell the Full Story
There are two systematic issues with benchmarks, which were already present in the community before the advent of LLMs but became worse after their appearance: what I call the investigation gap, driven by the exponential growth in the number of models, and data contamination, fueled by a similar explosion in the volume of scraped training data.
We will walk through these issues in the specific context of Portuguese NLP. As I will show, current benchmarks have significantly overstated recent advancements, and models trained specifically for Portuguese offer little to no real advantage over general-purpose alternatives.
- The Investigation Gap: There is limited investigation of models that weren’t explicitly designed for specific domains. Many models trained on substantial domain-specific data don’t advertise these capabilities, leaving their true performance potential unknown even to their developers.
One example of this investigation gap comes from Advancing Neural Encoding of Portuguese with Transformer Albertina PT-*, by Rodrigues et al..
The paper, submitted on 11 May 2023, releases Albertina, a family of encoders for Portuguese, and claims a new state-of-the-art over the BERTimbau Large model ( neuralmind/bert-large-portuguese-case ) on the ASSIN 2 RTE and ASSIN 2 STS datasets ( nilc-nlp/assin2 ).

However, the Albertina paper failed to consider xlm-roberta-large ( FacebookAI/xlm-roberta-large ), available since 2019, and deberta-v2-xlarge ( microsoft/deberta-v2-xlarge ), available since 2021.
xlm-roberta-large is advertised as an multilingual model, and deberta-v2-xlarge, although pretrained on massive amounts of Portuguese data, is advertised as an English model. Yet both models perform similarly to the Albertina models.
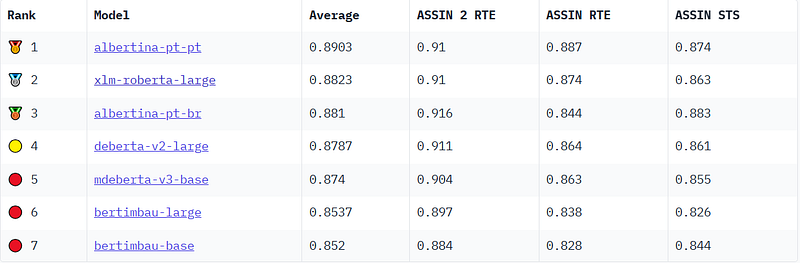
On the radar chart, this becomes clear: the orange line, corresponding to xlm-roberta-large, closely mimics the performance of the top model albertina-pt-pt, and even outperforms albertina-pt-br in some cases.
Both xlm-roberta-large and deberta-v2-xlarge perform significantly better than the comparison model used in the Albertina paper, bertimbau-large.

2. The Data Contamination Problem: Perhaps the most critical issue affecting benchmark reliability is data contamination, the inadvertent exposure of test sets during model training. This can artificially inflate performance metrics, since the model has already learned from the test set itself, creating misleading comparisons between models.
The risk of data contamination varies significantly across datasets. Newer, less widely-adopted datasets show lower contamination risk compared to well-established datasets that have been extensively replicated across the internet.
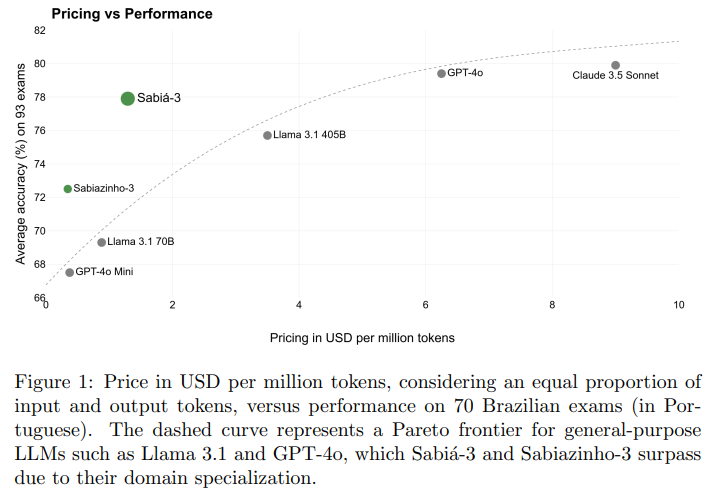
A relevant example comes from the paper Sabiá-3 Technical Report, by Abonizio et al.. Sabiá‑3 is a proprietary large language model developed by Maritaca AI for Brazilian Portuguese natural language tasks ( https://www.maritaca.ai/ ).
The report compares Sabiá-3’s performance with two similarly priced competitors, Llama 3.1 70B and GPT-4o Mini, on 93 Brazilian exams. Sabiá-3 is a clear winner, scoring significantly higher than the others.
However, the Napolab leaderboard tells a more nuanced story. As shown in the radar chart below, although Sabiá-3 outperforms its competitors on datasets widely adopted by the Brazilian NLP community (such as ASSIN 2 STS and ASSIN 2 RTE), it falls behind on lesser-known datasets like FaQUaD-NLI and HateBR, which are less likely to be contaminated.
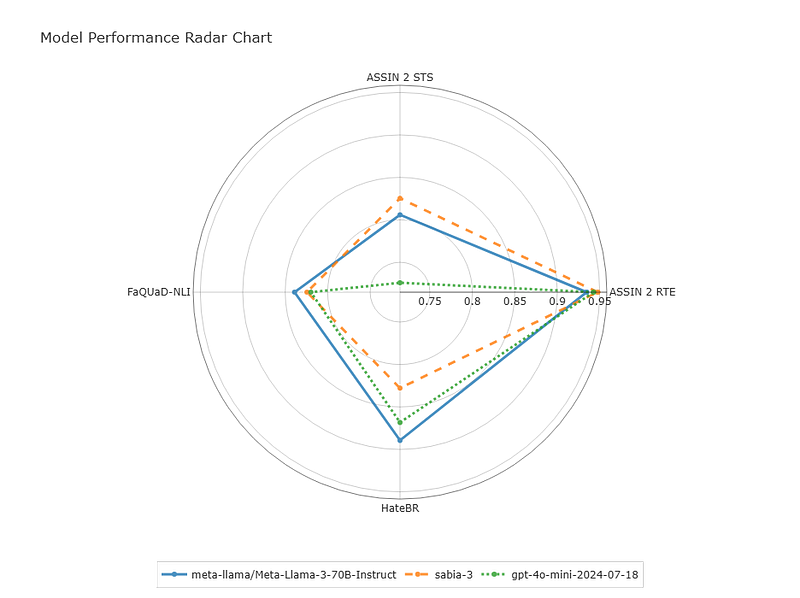
FaQUaD-NLI (ruanchaves/faquad-nli) and HateBR (ruanchaves/hatebr) were reformatted by me in 2023 during my Master’s research. Although the original data was collected by others, I defined the splits, established the evaluation format, and published the datasets on the Hub. While they’ve appeared in a few publications (such as TeenyTinyLlama: Open-Source Tiny Language Models Trained in Brazilian Portuguese, by Côrrea et al.), they haven’t seen broad community adoption, making them less vulnerable to data contamination.
Although studies on data contamination exist in the NLP community, many domains still lack robust investigations. That’s because while there’s motivation to publish benchmarks that favor your own model, there’s less incentive to review the literature critically or challenge established results.
Researchers from my alma mater, the University of the Basque Country, have done excellent work in this area. Their paper, NLP Evaluation in Trouble: On the Need to Measure LLM Data Contamination for Each Benchmark, by Sainz et al., is definitely worth a read.
If you’d like to take a deeper dive into these issues, I recommend exploring the Napolab repository and my Master’s thesis: Lessons Learned from the Evaluation of Portuguese Language Models.
The investigation gap and data contamination issues I uncovered in Portuguese NLP extend far beyond this domain. If you’re building benchmarks, be sure to challenge your assumptions. Progress in NLP depends not just on better models, but also on better ways of measuring them.